Intro
I had a chance to use the Random Intercept Cross-Lagged Panel Model (RI-CLPM) in one of my previous projects ([link]), and found it to be a useful alternative to the traditional CLPM, especially when trying to address some of its well-known limitations.
In my experience, RI-CLPM works particularly well for longitudinal data with repeated measures, especially when the research question is about within-person dynamics rather than between-person differences. If you are working with panel data in this context, it is probably worth taking a closer look.
The model was introduced by Ellen L. Hamaker, Rebecca M. Kuiper, and Raoul P. P. P. Grasman (2015) as part of a broader critique of the traditional cross-lagged panel model.
What is RI-CLPM?
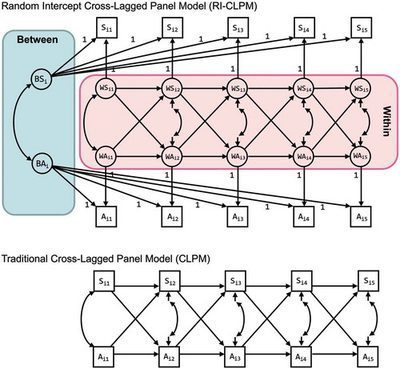
RI-CLPM is a variant of the traditional cross-lagged panel model (CLPM) that separates within-person processes from stable between-person differences.
In a standard CLPM, lagged effects are estimated on observed scores, which combine both trait-like stability and time-specific fluctuations. This makes the interpretation less clear, because the model does not distinguish whether an effect reflects changes within individuals or stable differences between them.
RI-CLPM addresses this by introducing random intercepts that capture time-invariant, person-specific means. The remaining variance can then be interpreted as deviations from an individual’s typical level, and the cross-lagged paths are estimated on this within-person component.
Why use it?
The main reason to use RI-CLPM is when the research question is about within-person change over time.
For example, instead of asking whether individuals with higher X tend to have higher Y, RI-CLPM allows you to ask:
- When a person is higher (or lower) than their usual level on X, does that predict a change in Y at the next time point?
In practice, this distinction often matters. What appears to be a longitudinal effect in a CLPM can, in some cases, be driven largely by stable between-person differences.
A simple way to think about it
One way to think about the model is:
observed score = stable person-specific level + time-specific deviation
The random intercept captures the stable component, and the lagged paths operate on the deviation part.
Because of this, autoregressive and cross-lagged coefficients are often smaller compared to CLPM, since trait-like stability is no longer being absorbed into the lagged structure.
Practical notes
A few practical points that came up while using the model:
- At least three waves are typically required
- Model complexity increases fairly quickly with additional variables
- Standard errors tend to be larger compared to CLPM
- Interpretation shifts to within-person processes, so the model should match the research question
Resources
For implementation, the following resource is very useful:
- RI-CLPM & Extensions website by Jeroen Mulder
It includes Mplus and R (lavaan) syntax, along with extensions such as multiple indicators, predictors, and multi-group models. I found it particularly helpful when setting up the initial model and checking different specifications.
Image source: RI-CLPM & Extensions website